Audiphon (Auditory models for automatic prediction of phonation) aims to build the foundations of the next generation of Automatic Phonation Recognition (APR)-systems. Using machine-learning techniques on features extracted from models that represent speech at different levels in the auditory system, Audiphon will provide phonation recognition methodologies with superior accuracy relative to those currently used in the study of under-resourced languages. It will also provide insights regarding the most adequate auditory representations for central speech-related phenomena, such as phonemic contrasts and allophone realization. Outcomes of Audiphon include software tools for APR and identification of auditory representations that best capture different phonation types (creaky, modal, breathy, etc.).
Automatic Speech Recognition—ASR systems are surrogates of human listeners, yet they are vulnerable to variations in the way a speaker delivers an utterance. ASR systems are unevenly developed across languages. For well-resourced ones, current ASR accuracy, measured as the number of substitutions, insertions, and deletions in a target sequence of words a.k.a. Word Error Rate—WER, is comparable to human accuracy (it is as low as ∼ 3% for English [1]). In contrast, the best WER for under-resourced languages is above 30% [2], as reported in a recent international challenge [3]. Interestingly, most of the target languages in this challenge (Cantonese, Vietnamese, etc.) use phonation (e.g., breathy, creaky, or modal voice) as a contrastive way to give meaning to an utterance. For instance, it has been reported that Dza, a language spoken mostly in the North-Eastern part of Nigeria, features minimal triplets such as /f`i /, /f`~i /, and /f`i ̈ / (meaning “ring,” “plant spike,” and “maternal uncle,” respectively) which only differ in the way the vowel is produced (oral, nasalized, and breathy, respectively) [4].
A possible reason for the accuracy mismatch between well- and under-resourced languages is the extensive use of features incapable of capturing crucial aspects of the auditory signal. The most common features fed into ASR Machine Learning (ML) algorithms are Mel-Frequency Cepstral Coefficients—MFCCs [5]. These coefficients effectively represent the speech signal in a manner closely resembling how humans perceive frequency (pitch) and intensity (loudness) in different auditory channels. However, MFCCs are less efficient at representing other important aspects of human hearing, such as frequency masking (where loud low-frequencies make it challenging to hear quieter high-frequencies), Sound Pressure Level—SPL-dependent gain control (where quiet sounds are more amplified than loud ones), etc. These aspects are of particular relevance to the different phonation types used in many under-resourced languages. To bridge the accuracy gap between well- and under-resourced languages in ASR systems, it is imperative to improve the way phonation is detected, possibly by mimicking what listeners do.
We have identified three main components of Audiphon:
- Linguistic component: We will use available speech recorded corpora, such as those provided in [8], as well as other corpora compiled by the authors. To date, we have collected corpora from nine languages (Burmese, Miao, Zapotec, etc.) totaling about 15,000 segments. The audio and phonation classification of these segments need to be re-examined. Some recordings may include unintended noise, and while some of these corpora have transcriptions, many require more precise segmentation and labeling. Preliminary reviews have revealed that the endpoints for segments (vowels, consonants, etc.) are not always exact. In addition, the assigned label of a segment often corresponds to dictionary entries rather than the actual utterance made by a speaker. Since the supervised learning approach used in Audiphon relies on accurate segments and labels, manual segmentation and annotation will consequently be used as required.
- Auditory component: Several models of the processing performed by the auditory system have been proposed in the literature (e.g., [9, 10, 11]) and several software implementations of such models also exist (e.g., [12, 13]). We will compare existing software implementations to establish the most efficient one for the phonemic classification task. Some of the models are limited to simulate the analysis performed in the basilar membrane (e.g., [9]) while others include the effect of the hair cells (e.g., [10]). Whether simpler models are sufficient for the apr proposed in Audiphon will be established in this component. To that end, we will process the speech recordings with these models and their outputs will be used in the machine learning component explained below. Note that because of the exploratory nature of this project, the results of the machine learning component will be also used to guide the selection of the most efficient auditory model in an iteratively manner.
- Machine learning component: We will compare different machine learning models, including Transformer-, Long-Short Time Memory (LSTM)-, and Gated Recurrent Unit (GRU)-based networks. These models are capable of processing time-series features extracted in the auditory component. Transformers are fairly newer than the other models and do not require that the time-series be processed in order. LSTMs and GRUs are specializations of Recurrent Neural Networks (RNNs). LSTMs are more computational demanding than the others, so the comparison between different ML-models will elucidate whether extra computational requirements are justified for Audiphon. In our previous research, we have successfully used LSTMs to predict phonation based on psychoacoustic features.
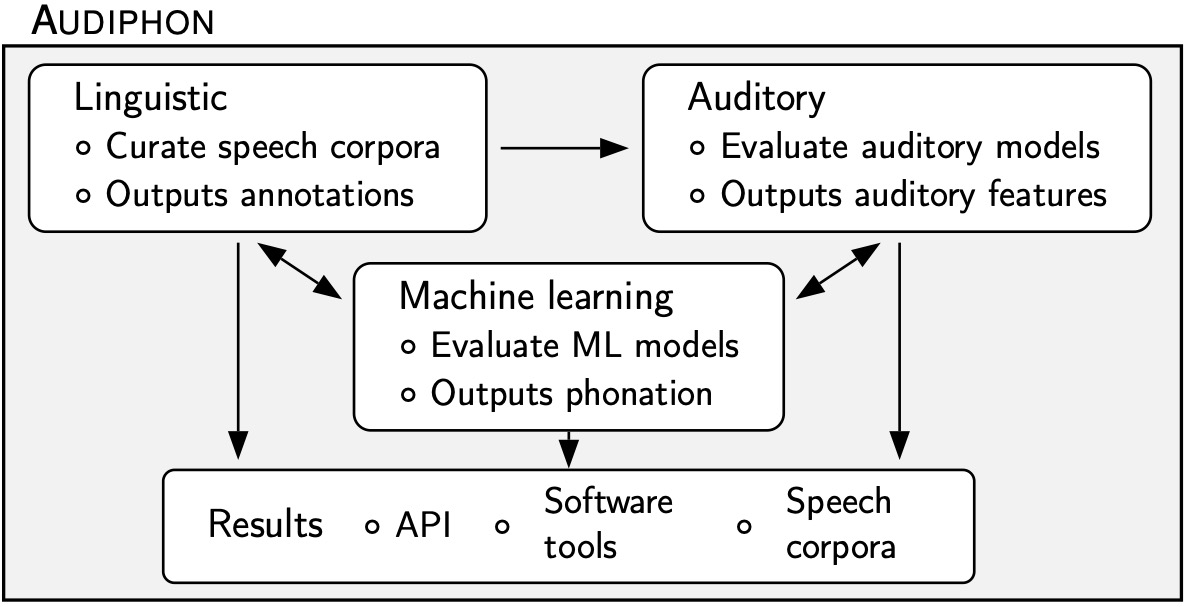
- Tools for speech researchers: Audiphon will produce software tools aimed to end-users for automatic segmentation, phonation classification, and manual phonation classification for experts, so that the unknown phonation of a given segment can be assessed by consensus among several judges. Software created within Audiphon will be placed in public repositories under “Modified BSD License,” which imposes minimal restrictions on its use and distribution. This way we will foster the adoption of our methods by the industry.
- Speech corpora and dissemination: Speech recordings along with metadata (segmentation and labels) acquired through fieldwork will be organized in public corpora for documentation and preservation purposes. Research publications in Q1 journals and prestigious international conferences will inform the scientific community of our research results.
- API for software developers: We will provide an Application Programming Interface (API) for automatic phonation recognition, so this can be easily included in third-party systems, such as asr. We will evaluate the superiority of our system by comparing its results with those of state-of-the-art predictors. These predictors are mainly based on acoustic features like spectral tilt (the slope of speech’s power spectral density) [6], articulatory features (e.g., open quotient, which represents the fraction of a glottal cycle during which the glottis is open) [7], or rely on inadequate features, as previously discussed.
Significance
Audiphon would help to bridge the asr accuracy gap between under- and well-resourced languages, contributing directly to the Sustainable Development Goal SDG-10 (reducing inequality within and among countries).
Originality
As mentioned before, predictors of phonation have been mostly based on acoustic, articulatory, or on inadequate features. Auditory models have been successfully used in voice activity detection and speech separation [14]. They have also been used in speech enhancement systems in adverse noisy conditions [15]. Importantly, a binary classifier trained with auditory features extracted from speakers of one language outperformed classifiers trained with mfccs when presented with speech from a different language [13]. A comprehensive study on the use of auditory features in automatic phonation recognition, and speech technologies in general, is still to be performed. Audiphon can push the limits of our understanding of speech perception and speech technologies. Since auditory features are universal (i.e., independent of language), using these features in ASR systems could become a breakthrough in the field.
References
- A.-L. Georgescu, A. Pappalardo, H. Cucu, and M. Blott, “Performance vs. hardware requirements in state-of-the-art automatic speech recognition,” J. on Audio, Speech, and Music Proc., 2021.
- T. Alumäe and J. Kong, “Combining Hybrid and End-to-End Approaches for the OpenASR20 Challenge,” in Proc. Interspeech, pp. 4349–4353, 2021.
- K. Peterson, A. Tong, and Y. Yu, “OpenASR20: An Open Challenge for Automatic Speech Recognition of Conversational Telephone Speech in Low-Resource Languages,” in Proc. Interspeech, pp. 4324–4328, 2021.
- N. Othaniel, “A phonetic study of breathy voicing in Dza,” Master’s thesis, Université Paris Cité, Paris, 2022.
- A. Singh, V. Kadyan, M. Kumar, and N. Bassan, “ASRoIL: a comprehensive survey for automatic speech recognition of Indian languages,” Artificial Intelligence Review, 53(5), pp. 3673–3704, 2020.
- P. Keating, C. Esposito, M. Garellek, S. Khan, and J. Kuang, “Phonation contrasts across languages,” in UCLA Working Papers in Phonetics, no. 108, pp. 188–202, 2010.
- D. H. Klatt and L. C. Klatt, “Analysis, synthesis, and perception of voice quality variations among female and male talkers,” J. Acoust. Soc. Am., vol. 87, no. 2, pp. 820–857, 1990.
- “Production and perception of linguistic voice quality,” 2007. http://www.phonetics.ucla.edu/voiceproject/voice.html.
- M. Slaney et al., “An efficient implementation of the patterson-holdsworth auditory filter bank,” Tech. Rep. 35, Apple Computer, Perception Group, 1993.
- R. F. Lyon, Human and machine hearing. Cambridge University Press, 2017.
- R. Meddis, “Simulation of mechanical to neural transduction in the auditory receptor,” J. Acoust. Soc. Am, vol. 79, no. 3, pp. 702–711, 1986.
- P. Majdak, C. Hollomey, and R. Baumgartner, “AMT 1.0: the toolbox for reproducible research in auditory modeling,” Acta Acustica, 2021.
- A. Gutkin, “Eidos: An open-source auditory periphery modeling toolkit and evaluation of cross-lingual phonemic contrasts,” in Proc. 1st Joint Wkshp. spoken language technologies for under-resourced languages, pp. 9–20, 2020.
- S. Pan, Cochlea modelling and its application to speech processing. PhD thesis, University of Southampton, 2018.
- D. Baby and S. Verhulst, “Biophysically-inspired features improve the generalizability of neural network-based speech enhancement systems,” Proc.Interspeech, pp. 3264–3268, 2018.
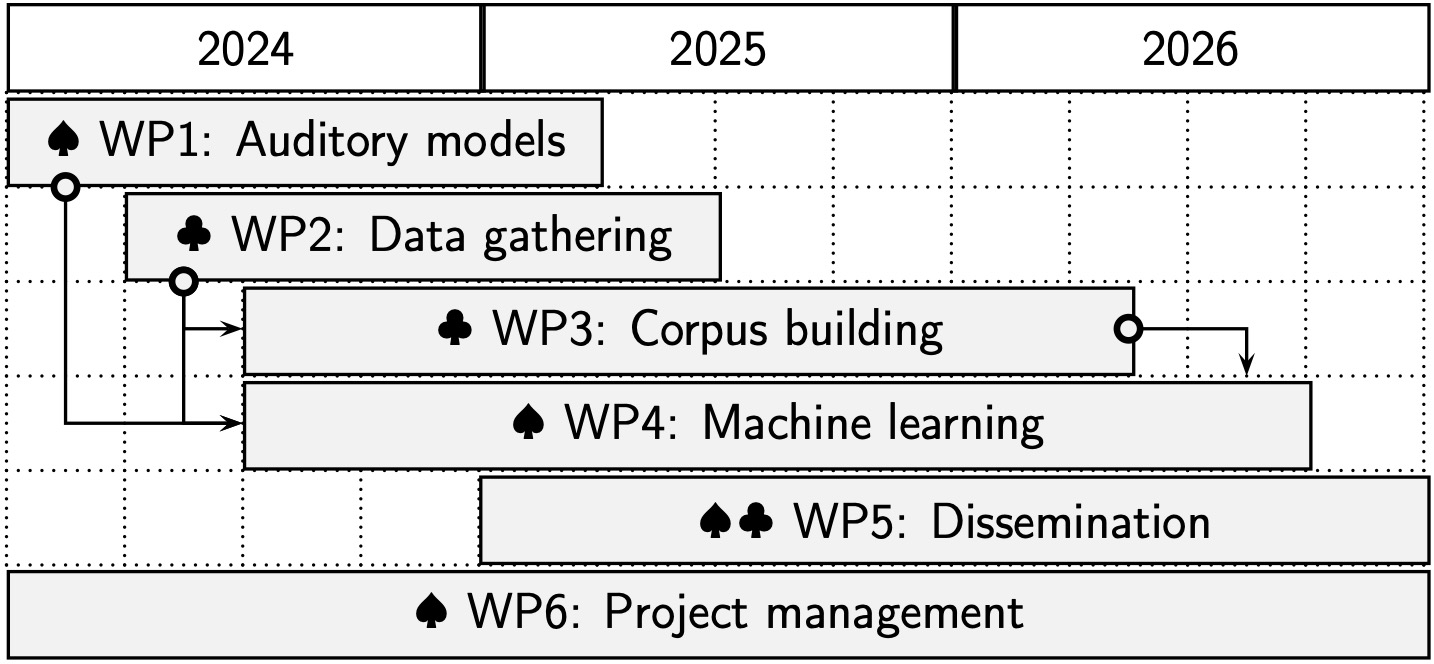 We have divided Audiphon into six Work Packages (WPs), as shown in the figure on the right. WP1 tackles issues regarding the selection of auditory models to use for the machine learning algorithms. WP2, those related to data acquisition, including fieldwork recording, annotating, and evaluating acoustic recordings of speech. We will focus on languages
that use a three-way phonemic contrast (creaky, modal, and breathy), such as Mixe and Zapotec, spoken in some regions of Mexico. When acquiring new corpora, we will perform glottographic and other articulatory recordings for completeness; the organization of these recordings into corpora are covered in WP3. Tasks related to ML-phonation classification (development, training, and evaluation of ML-models, etc.) will be conducted in WP4. This WP requires pre-existing corpora and corpora acquired during the project. WP5 and WP6 are related to dissemination activities (publications, presentations, etc.) and general administration of the project (website management, reports, etc.), respectively.
The leader of each WP is indicated by spade (♠) and club (♣) suits for Prof. Villegas and Prof. Lee, respectively. Machine learning, statistical modeling, and phonetics are fields where Prof. Villegas has substantial research experience. His team will be in charge of WP1, WP4, and WP6. Prof. Lee is an expert on phonetics and phonology of understudied languages with special interest in those where phonemic contrast is used. He will lead the activities of WP2 and WP3. Activities of WP5 will be collaboratively conducted by both groups.
We have divided Audiphon into six Work Packages (WPs), as shown in the figure on the right. WP1 tackles issues regarding the selection of auditory models to use for the machine learning algorithms. WP2, those related to data acquisition, including fieldwork recording, annotating, and evaluating acoustic recordings of speech. We will focus on languages
that use a three-way phonemic contrast (creaky, modal, and breathy), such as Mixe and Zapotec, spoken in some regions of Mexico. When acquiring new corpora, we will perform glottographic and other articulatory recordings for completeness; the organization of these recordings into corpora are covered in WP3. Tasks related to ML-phonation classification (development, training, and evaluation of ML-models, etc.) will be conducted in WP4. This WP requires pre-existing corpora and corpora acquired during the project. WP5 and WP6 are related to dissemination activities (publications, presentations, etc.) and general administration of the project (website management, reports, etc.), respectively.
The leader of each WP is indicated by spade (♠) and club (♣) suits for Prof. Villegas and Prof. Lee, respectively. Machine learning, statistical modeling, and phonetics are fields where Prof. Villegas has substantial research experience. His team will be in charge of WP1, WP4, and WP6. Prof. Lee is an expert on phonetics and phonology of understudied languages with special interest in those where phonemic contrast is used. He will lead the activities of WP2 and WP3. Activities of WP5 will be collaboratively conducted by both groups.
Julián Villegas (P.I., University of Aizu): https://onkyo.u-aizu.ac.jp/
Seunghun Lee (Co-P.I., International Christian University): https://researchers.icu.ac.jp
Ambrocio Gutierrez Lorenzo (Collaborator, University of Colorado Boulder): https://www.colorado.edu/linguistics/ambrocio-gutierrez-lorenzo
Jeremy Perkins (Collaborator, Joint researcher with Research Institute for Languages and Cultures of Asia and Africa): http://jerperkins.ca/
2025- I. de la Cruz Pavía, J. Villegas, C. Nallet, K. Iwamoto, R. Guevara, and J. Gervain, "The role of syllabic rhythm in speech perception across languages," Scientific Reports, vol. 15, no. 1, p. 24494, Jul. 2025. DOI: 10.1038/s41598-025-07053-y.
- J. Perkins, S. J. Lee, and J. Villegas, “The interaction between tone and duration in Du’an Zhuang,” J. of the Int. Phonetic Assoc., Apr. 2025. DOI: 10.1017/S0025100324000239.
- Y. Sakai and J. Villegas, "Detection of Parkinsonian speech using auditory features," J. Acoust. Soc. Am., vol. 158, no. 4_Supplement, pp. A443–A443, Oct. 2025. DOI: 10.1121/10.0041452.
- J. Villegas and S. J. Lee, "A meta-analysis of phonation research in the past 10 years," in Proc. 39th General Meeting of the Phonetic Society of Japan, Sep. 2025, pp. 31–35.
- A. G. Lorenzo, S. J. Lee, and J. Villegas, "Interaction of phonation and tone in San Miguel del Valle Zapotec," in Proc. 39th General Meeting of the Phonetic Society of Japan, Sep. 2025, pp. 27–30.
Project title: "Auditory models for automatic prediction of phonation".
This project is supported by JSPS KAKENHI Grant Number 24K03872.

University of Aizu